1. Abbreviation Explanation
Here are the abbreviations that will be mentioned afterwards, you don’t need to know the exact meaning, just what it probably expresses:
- LLM: Large Language Model
- RAG: Retrieval Augmented Generation
- Mate: An application that can query Confluence or Bitbucket
2. Metaphor of LLM and RAG
We have all taken important exams. To prepare, students must study the textbook, attend lectures, and research any questions they have. After reviewing the material, it is time to take the exam. Exams come in two types: closed-book and open-book.
During closed book exams, students must read the questions and conditional hypotheses, search their memory for relevant knowledge, and then write their answers in the space provided at the back. In contrast, during open book exams, students are allowed to refer to their books or notes, and write down the relevant information and what they have memorised.
The student is an LLM and learning knowledge means pre-training of the model. As professors or examiners, we ask the LLM questions and expect the answers. Closed book means that the answer does not rely on any external knowledge, but rather than on the parameters stored in the brain. On the other hand, RAG is an open-book exam, where the student LLM acquires knowledge related to the question through a vector query before answering.
All processes related to data training or fine-tuning fall under the umbrella of LLM. This includes vector queries, vector database extraction, prompt construction, and more. RAG, on the other hand, is more engineering-related. The core of LLM is wrapped within the big concept of RAG.
3. LLM
For a clear and comprehensive explanation of LLM, I highly recommend watching the video (1hr Talk) Intro to Large Language Models. The video covers all the essential aspects of the topic and is the best resource I have come across.
3.1 Understanding of Transformer
The paper ‘Attention is all you need’ introduced the Transformer model, which sparked the GPT boom. You can find the paper at this link: Attention Is All You Need.
To comprehend the Transformer, I recommend perusing this straightforward explanation titled “The Illustrated Transformer ” rather than paper. The blog post presents a clear and concise overview of how the Transformer operates.
It is important to note that LLM and Transformer are not equivalent, despite the common assumption due to the success and popularity of the latter. Furthermore, while GPT is a variant of the decoder component of Transformer, it is not an exact equivalent; for simplicity, it could be thought of as Transformer ≈ GPT ≈ LLM.
To enhance understanding of GPT, watch this Youtube video by Andrej Karpathy Let’s build GPT: from scratch, in code, spelled out and check out the corresponding open source code minGPT on GitHub. In the video, the author takes a code perspective as he builds a GPT model from scratch.
3.2 Understanding of LLama
OpenAI is the publisher of ChatGPT. However, despite its name, the model is not open source. Therefore, the open-source community has put in a lot of effort, particularly with the Llama model, which has been trained and open-sourced by Meta. The Llama model comes in sizes 7B, 13B, and 70B.
Meta has made almost everything related to Llama-Series open source:
Because Llama is open source, the community has fine-tuned and structured many models based on it. One of the most famous is the series of models from Mistral (France), according to their official website, the performance of the Mixtral 8x7B is similar to that of the GPT-3.5.
Most open source models are available on Huggingface with model parameters and free downloads. Meanwhile, Huggingface provides a leaderboard to test the performance of these models. However, it is important to note that public lists may not be entirely trustworthy due to the contamination issue . For a more persuasive list, please refer to the 🏆 LMSYS Chatbot Arena Leaderboard, which is voted on by humans.
3.2 Usage of Model
Although training the model requires significant GPU resources, expensive hardware is not necessary to load and use it. The model can also be run directly from a MacBook.
To run Llama2, for example, we can download the model files based on Huggingface: Download, and use the Transformers library to load and run the model directly. However, both loading and running the model can be very slow, as confirmed by actual testing. Part of the reason is that the default parameter precision of Huggingface is set to float32 (as shown in the Description ) and it cannot utilize the GPU on the MacBook.
To speed up model loading and usage, the open-source community has developed tools such as llamacpp , Ollama or vllm. There tools are written in CPP and can read models in quantized gguf format (more quantized models can be found here). This format is fast and efficient, and also takes advantage of GPU performance. The backend core service can be invoked locally using Bash commands or APIs. The return format is in OpenAI-specific JSON format, which is designed to facilitate easy connectivity to different front-ends.
The tools mentioned above are only suitable for loading and using specific model types. Additionally, Apple has released a tool called mlx for Apple Silicon memory, which effectively utilises the unified memory within the M-series chip.
3.3 Fine-tuning
As previously mentioned, fine-tuning is only applicable to models. By providing the model with specific data for training, the model acquires the corresponding knowledge and style of expression. This approach also addresses the issue of the model’s limited token acceptance.
Although fine-tuning with small data is effective, it can still be costly in terms of GPU resources. I attempted to fine-tune the Llama2-7b model using Google Colab, which is more affordable, but due to hardware limitations, the trained model cannot be exported for use in a production environment. Please refer to the following steps for the experiment: Fine-Tune Your Own Llama 2 Model in a Colab Notebook. The article Building LLM applications for production also compares the difference between Prompt and Fine-tuning.
Fine-tuning Mate at this stage is challenging due to cost and data security constraints.
4. RAG
RAG stands for
- Extract Information
- Augment Information
- Generate Results.
It is like an open-book exam where we provide relevant information to the LLM so that it can give less illusory answers. RAG is an abstract conceptual framework and does not imply a concrete implementation. Therefore, we can choose any module we need, depending on the requirements. It is a very efficient way to do this, even if OpenAI has a very positive opinion about it.
The LLM can provide more accurate answers when given relevant information, similar to an open-book exam. RAG is a conceptual framework and does not require a specific implementation. Modules can be chosen based on specific requirements. OpenAI has expressed a positive opinion about this efficient approach.
A simple architecture diagram is shown below, which comes from the RAG open source framework LlamaIndex, which is also used as the application framework by Mate.
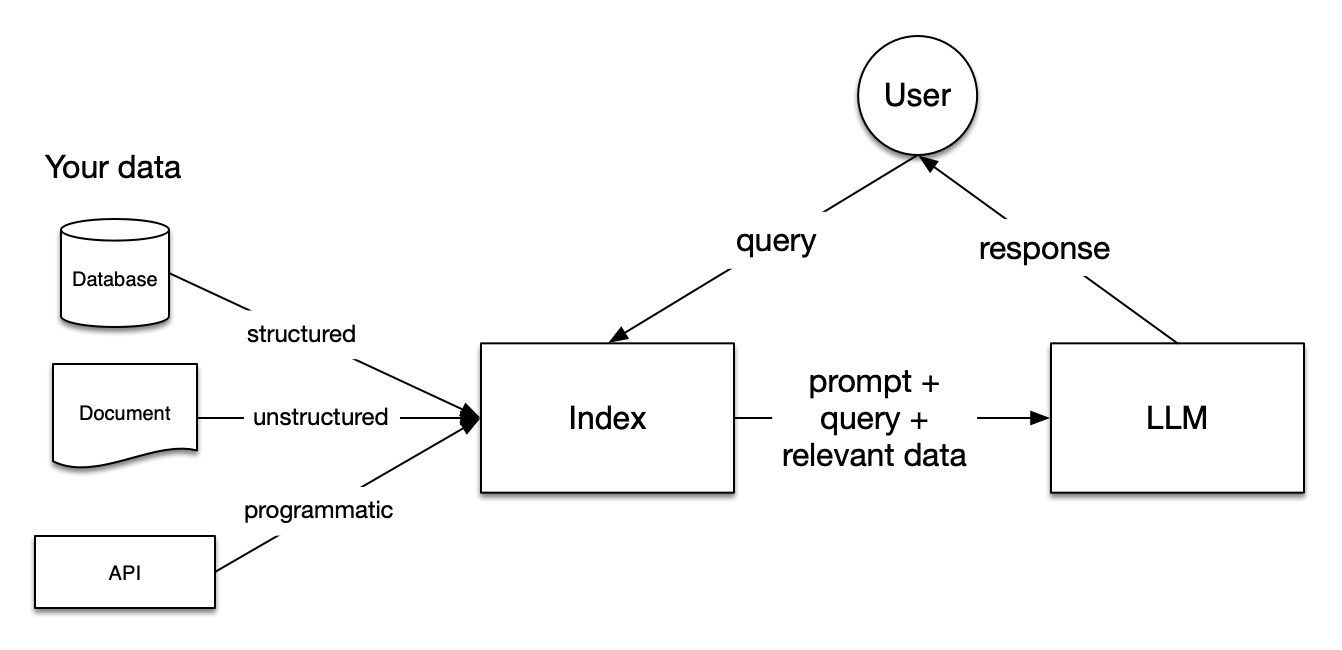
To understand the RAG concepts, it is recommended to read the original article, which provides a detailed explanation of the diagram and the concepts. The article can be found at here.
The diagram below is detailed and clearer than the flowchart above. It comes from the Copilot group on Github, who also share their experience in making LLM apps in their blog:
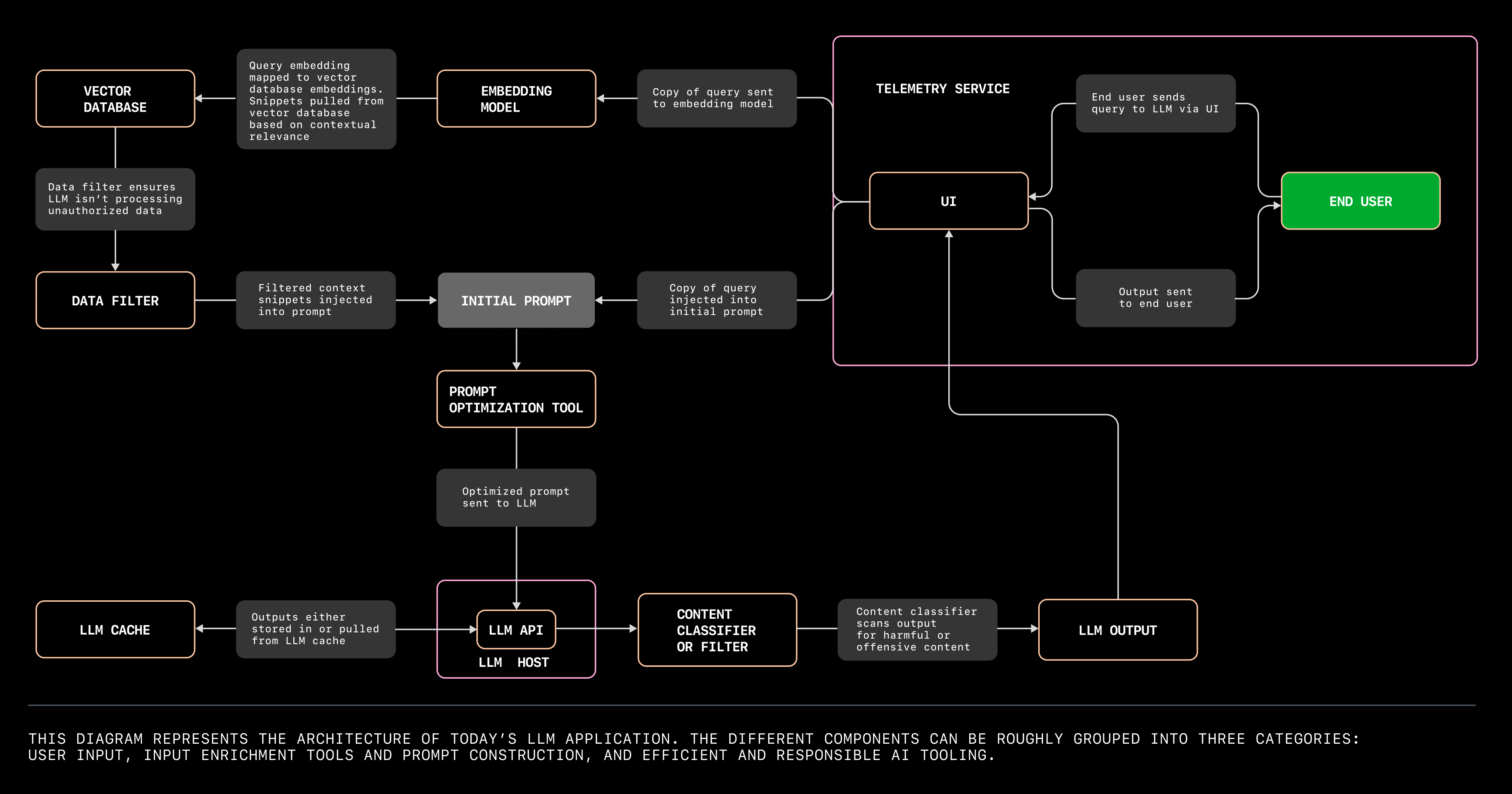
4.1 RAG’s journey
The journey begins with a user’s question or query.
The user inputs a question/query into the GUI interface of the front-end (MS Teams for Mate). The back-end (Python code deployed in a VM) receives the query and converts it into a vector using an embedding model. For more information on embedding models, please refer to this article: https://huggingface.co/blog/getting-started-with-embeddings.
The query vector is then inputted into a pre-prepared vector database, which retrieves the most relevant chunks. Various vector databases are available, and this article on Vector Stores compares their performance. Compared to a standard database, this type of database can store extremely long arrays of vectors. It also supports various algorithms for comparing similarities between vectors, such as calculating a cosine value to extract the text that is most similar to a query. This process is known as Retrieval.
After extracting the relevant chunks from the database, it has to undergo additional processes, such as filtering and reordering. This step corresponds to the Augmented stage in RAG.
We now have the user’s query in one hand and the relevant chunks from the database in the other. Next, we will input them into the prompt template so that the LLM can detect them correctly.
It is important to note that different LLMs use various system prompts for training, for example, the Llama2 model uses <s>[INST] <<SYS>> (reference), while the dolphin model uses < system> <human> (ref). The system prompts greatly affect the results.
Finally, the LLM processes all the prompts and returns a response to the user.
5. About LLMOps
According to databricks, LLMOps primarily focuses on improving and deploying models to enhance the value of the core LLM for the product. For instance, a better LLM in the case of RAG enables the output to extract information from chunks in a more logical and precise way.
LLMOps is appealing to both medium and large teams or companies due to their possession of ample private data and financial resources. They aim to enhance the effectiveness of their products through a stable and efficient process.
In contrast, LLMOps may not be as attractive to smaller teams. The reason for this is that the open source community has provided models with sufficient performance, while more and more important work has focused on processing the input information, e.g. how to get the chunks correctly, how to generate useful meta-information, or how to use better prompts.
For a project that is progressively growing from small to large, it is necessary to first improve performance outside of LLM. If a bottleneck in system performance is reached, such as LLM not providing correct feedback, generating hallucinations, or requiring subtle optimizations such as changes in LLM’s speech tone, it is necessary to address these issues in order to build an efficient LLMOps.
6. Summary
This short article introduces the development and use of LLM, showing the structure of RAG and how it relates to LLM. The length of the article is limited, for more detailed information please refer to the videos and links in the article.

